“东华杯”2021年大学生网络安全邀请赛暨第七届上海市大学生网络安全大赛
本文最后更新于:1 年前
MISC
checkin
题目描述:
+AGYAbABhAGcAewBkAGgAYgBfADcAdABoAH0-
解题思路:
去掉±号base64解码试出来了flag:flag{dhb_7th},纯属巧合,说一下后来知道的utf-7原理吧
知识点:
UTF-7编码的规则及特点为:
1)UTF16小于等于 0x7F 的字符,采用ASCII编码;
2)UTF16大于0x7F的字符,采用Base64编码,然后在首尾分别加上±;
3)UTF-7编码后,所有字符均小于等于 0x7F。
如字符串"A编码示例bC+123"的UTF-7编码为字符串"A+fxZ4AXk6T4s-bC±123"。"+fxZ4AXk6T4s-"中的fxZ4AXk6T4s是"编码示例"的Base64编码;"±"表示字符+;其余的保持不变。
附上在线网站:UTF-7 Decoder
project
题目描述:
一个普普通通的工程文件
解题思路:
伪工控题,离谱
按修改时间排序,21年的只有text.exe,双击运行一下出现一个压缩包,解压后拖到010,有三段邮件
是个eml邮件,加后缀后可通过qq邮箱/outlook打开
第一段base64,大部分解密出表情包吧啦吧啦那段文字,少部分报错
附上顺手发现的可换表的base解码网站:base系列 Decoder
第二段quoted-printable,内容还是那段文字
第三段base64转图片,得到鬼畜表情包。。。。
从邮件另存为的jpg和jfif文件头不一样,原因不明,但后来发现jpg中附加字符无了

stegdetect扫了一下,有概率是jphide但没有密码
——这就是当天所有成果了。。。我是菜鸡
文本在逐字删除时有卡顿,且存在大量E2 80 8C(大佬说的我不理解),说明存在零宽字符,解密得hurryup

把jfif拖进stegsolve里面发现有additional bytes


附加字符串+特征值判断OurSecret,用hurryup解密发现有名为f14g的文件,内容就是flag:flag{f3a5dc36-ad43-d4fa-e75f-ef79e2e28ef3}
知识点:
零宽字符
1 | |
可用于文本加密,文章水印,逃脱敏感词匹配等方面,可转换为二进制加密或Morse编码加密
三个解密网站:decode1,decode2,decode3(不一定成功),一个检测网站
OurSecret(原理暂不清楚)

JumpJumpTiger
题目描述:
flag格式为flag{uuid}
解题思路:
拖进ida看到hint,大意是奇偶数分离

发现可疑长字符串,从2600h到7D465Fh位置,利用winhex拷出来存入output.txt
1 | |
大佬的话:对png做pngcheck,做zsteg发现没东西。但是两张图像作个差,发现有横竖的线,这是盲水印的特征
1.png和1.jpg大小不同,内容一致,猜测盲水印,得到flag:flag{72f73bbe-9193-e59a-c593-1b1cb8f76714}
1 | |

where_can_find_code
题目描述:
无
解题思路:
vim或010打开,能发现奇怪的东西
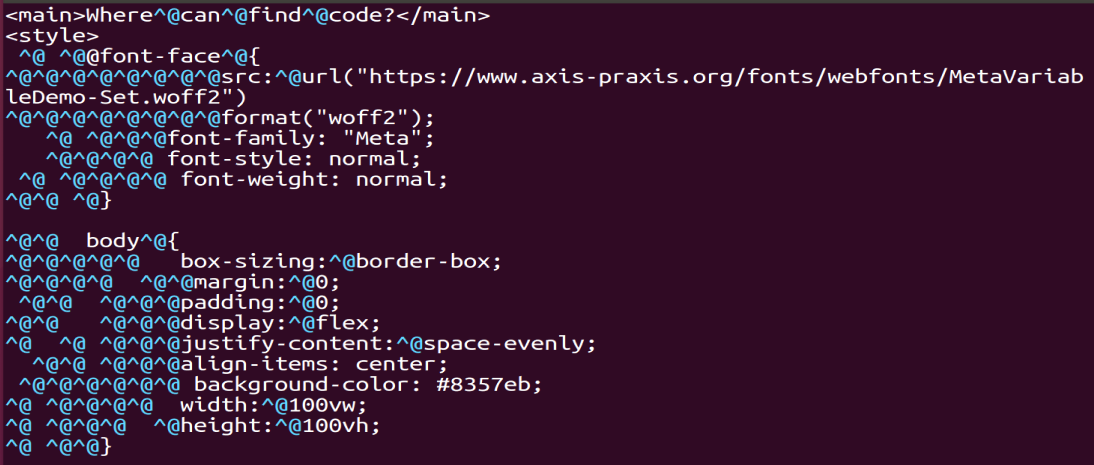
在winhex中确认是wbstego隐写,wbStego4.3open解密得20810842042108421
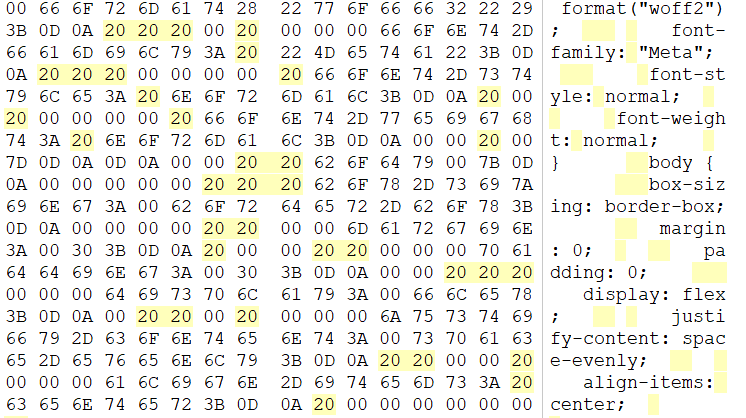
只由01248组成为云隐密码,脚本解密得BINGO
1 | |
谷歌搜索format(“Translate the letter J into I”);找到网站。。。。。合理上网我吐了
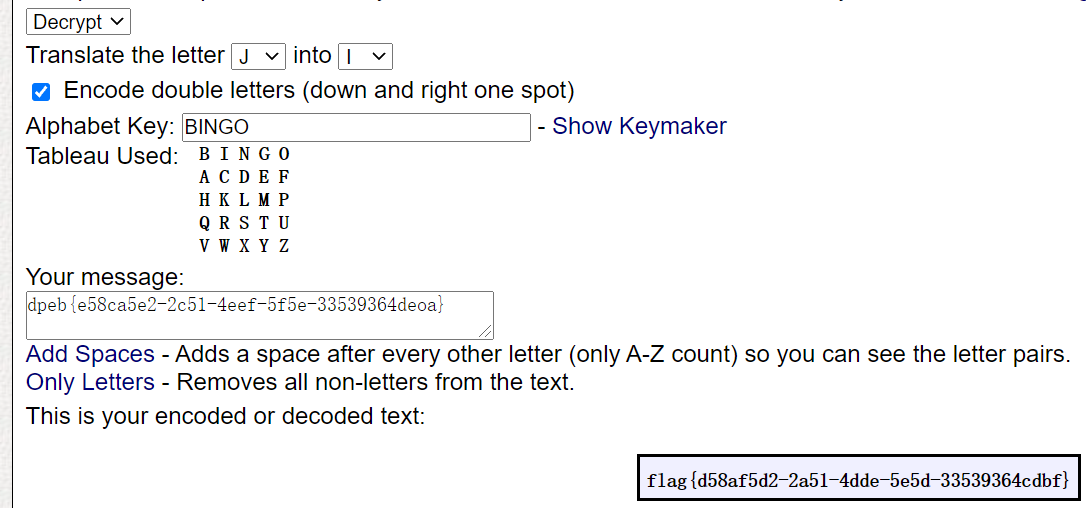
得到flag:flag {d58af5d2-2a51-4dde-5e5d-33539364cdbf}
知识点:
wbStego4open是一个隐写开源工具,它支持Windows和Linux平台。 你可以用wbStego4open可以把文件隐藏到BMP、TXT、HTM和PDF文件中,且不会被看出破绽。 还可以用它来创建版权标识文件并嵌入到文件中将其隐藏。 wbStego在插入数据时(此处以非加密的版权信息为例),充分利用了插入法和LSB修改法两种技术。 wbStego4open会把插入数据中的每一个ASCII码转换为二进制形式, 然后把每一个二进制数字再替换为十六进制的20或者09,20代表0,09代表1。 例如,在wbStego4open的版权管理器(Copyright Manager)中,输入一个包含“Oblivion”的地址, wbStego4open就会将其由ASCII码转换成相应的二进制码, 然后再用0x20和0x09替换每个二进制数。
云影密码(01248密码)
英文字母从a到z一共有26个,此时我们可以用某些特殊的数字来替换字母,云影密码也就因此出现。
云影密文只由5个数字组成:01248,那么,如何使用这5个数字代表26个英文字母?
云影加密用的是加和的方式,即:1-26之前的数字都可以用1248这四个数字来加和得到,有了密文与明文之间的对应关系。引入0来作为间隔,以免出现混乱。
1 | |
举个例子:huluxia这七个字母加密之后就是801488048014880448801801
有一个问题,那就是既然是加和的方式,加密后的密文就不会只有一种,比如上面的例子,还可以是11240144480228014880888014401
解密时,直接将0分隔开的几个部分分别加和,然后按字母表顺序找对应位置的字母就行
reverse
两道安卓的先列这之后再说
hello
题目描述:
hello world!
解题思路:
Hell’s Gate
题目描述:
Welcome to the hell’s gate!
解题思路:
mod
题目描述:
花花总喜欢把东西隐藏起来。
解题思路:
各种栈指针不平衡反编译出错,看到相邻跳转和各种call,很明显是花指令
从0x401203~0x401221全部nop掉,从0x4013E4~0x4013EF全部nop掉,发现还有不平衡的上下多nop掉0x401222的db36,删除掉被nop部分的函数,之后c一下转换为代码(可以省略),p重新声明函数,再次反编译。
去掉花指令后很清晰,关键代码如下:
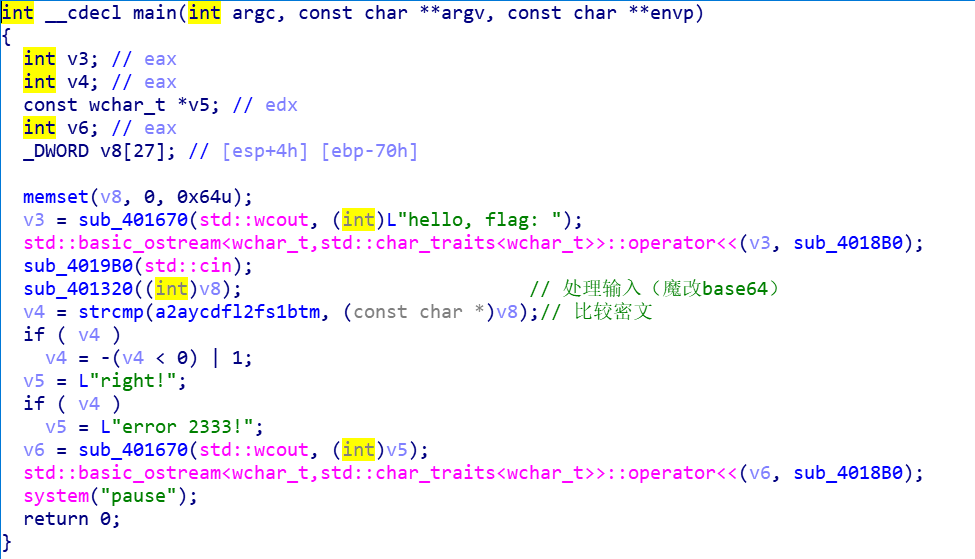
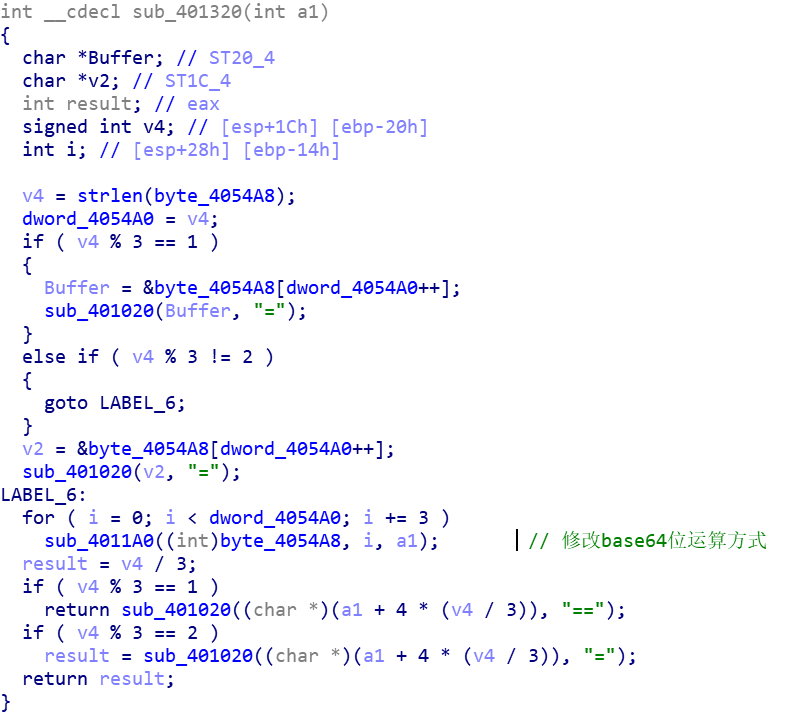

既然知道魔改base64,写脚本的方法还挺多的,①z3应该是最直观的,还可以②爆破,即先打表所有4byte base64编码字符串到3byte明文的映射,然后在解码的时候查表,③纯逆向。。。反正我做不到,
1 | |
得到flag:flag{5a073724-8223-413d-11fa-d53b133df89e}
ooo
题目描述:
如何解呢?
解题思路:
根据关键字符串定位函数,sub_418970作用没搞懂,像是转换成unti32?
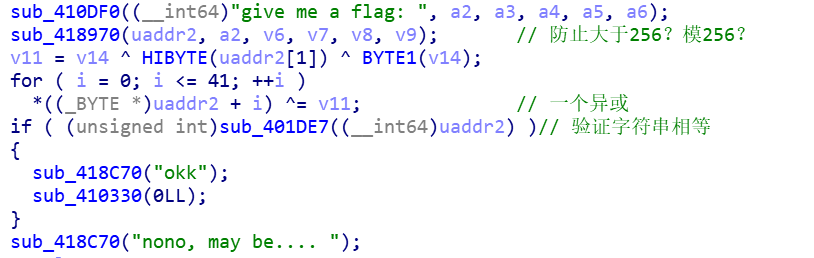
关键字符串被^0x17加密过
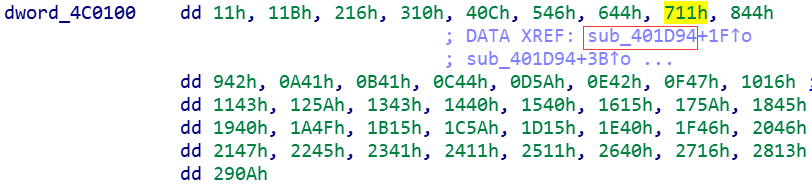
爆破yyds
1 | |
得到flag:flag{13f35663-50a4-477b-278b-b711026ff7ad}
参考wp:
reverse:ZM.J,Mas0n,寒江寻影,Tiany^ ^(救我花指令)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!